Character encodings and a bit of Python
I’ve been wanting to write about character sets and encodings for a while, since I had problems in the past understanding what is it all about?
Words and information
When reading this, all you are seeing is an arrangement of characters disposed in a certain way that they are meaningful to you. – for instance “blank” separations between words are an indication of different words – so this give us an idea that, the way in which symbols are disposed mean something. And they mean something thanks to a set of gramatical rules that lead to a consensus on how to write words that represent information. In everyday communication we don’t have to deal with more than the grammatical words, but for computers it is a bit more complex. Remember that computers are all about binary digits 0 and 1 and everything in a computer has to be that way, so how do we tell computers to represent the alphabet?, well, we need a code for that.
A code – not to be confused with source code – is a set of of symbols, words or characters an rules that can be used to represent other words, symbols or characters. In other words, a code is a system that allows to represent information from a given representation into another. A relevant example of how different symbols can represent the same information is the Roseta Stone, which shows three versions of a decree given at the city of Memphis, the stone allowed archeoligist to decode old egyptian symbols to their greek equivalent representation

Wait, what does this have to do with encoding?
Like the Roseta Stone, computers need different representations for the information, so the first hint is that encoding has to do with the way in which certain information is represented in the computer. To make things clearer, consider the five vowels a, e, i, o, and u. We could use binary digits and create the following code – our own Roseta Code –
Vowel -> Symbol
a -> 000
e -> 001
i -> 010
o -> 100
u -> 011
We could write the sequence i i i as 010 010 010 and we would say that we have an encoding scheme. If we where to use 7 bits to represent characters, we could represent 2^7 = 128 different symbols. We could represent 26 lower case letters, 26 upper case letters, punctuation symbols and other non readable symbols and we would end up with a code known as ASCII Code which stands for American Standard Code for Information Interchange. A “Roseta Stone” between binary digits and ASCII characters looks like this,
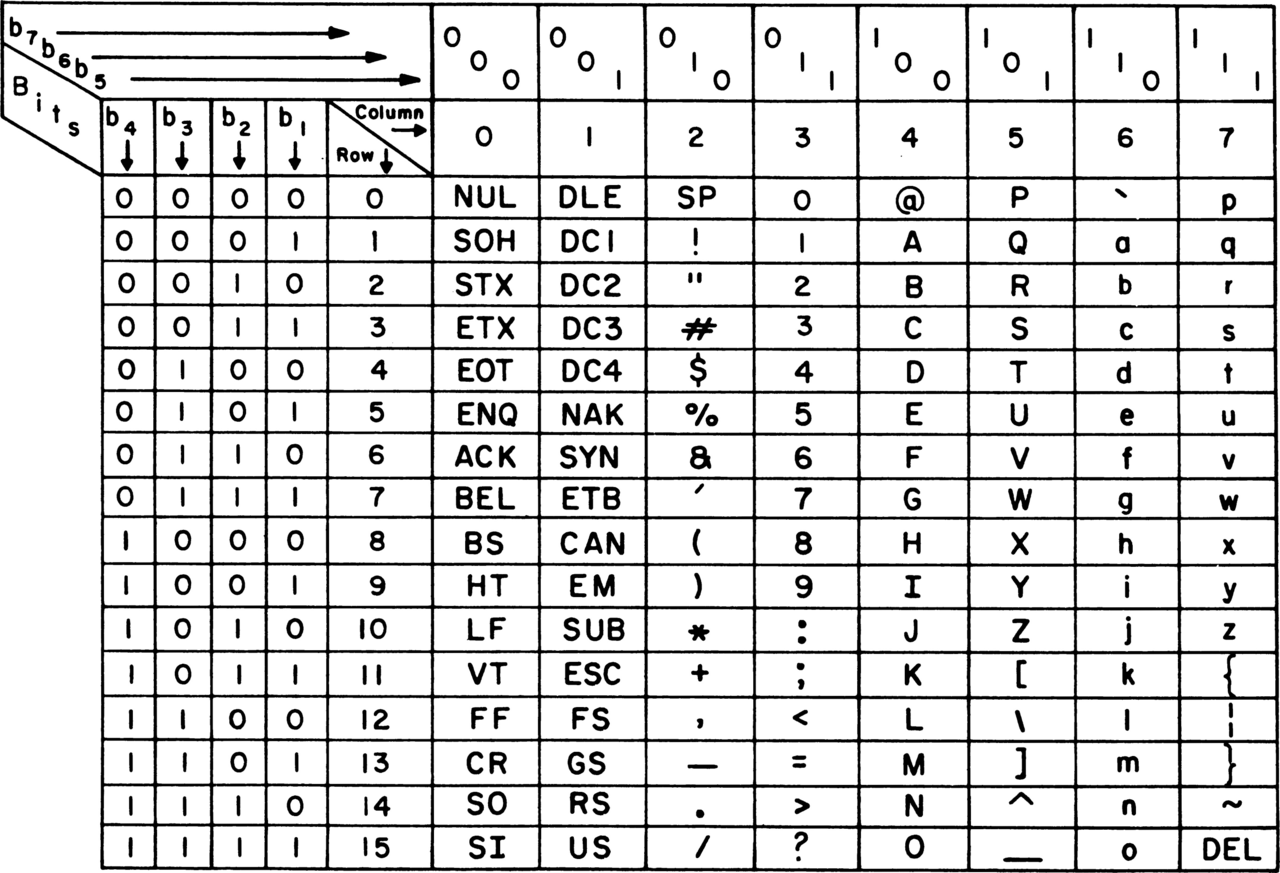
But, are 128 symbols, or “codes point” enough?
Character Sets
If the only language in the world where English, ASCII would be okay to represent all symbols, but the rich diversity of languages and symbols do not fit within 7 bits. Soon enough the Unicode standard appeared as an attempt to reconcile most of the world written characters into a single code table –yes, yet another roseta stone for characters– that could be use to write virtually with any language, adding the feature that we can use different number of bits to represent the same character, so the Unicode standard defines UTF-8, UTF-16, and UTF-32, so we can use 8, 16 and 32 bits to represent characters. Take for instance,
Representation of character "A" with different bit sizes
UTF-8 -> 01000001
UTF-16 -> 00000000 01000001
UTF-32 -> 00000000 00000000 00000000 01000001
Playing with python code
In python we can check the encoding table with simple instructions
# Define an unicode string
In [1]: a = u"A"
# Put its encoding to utf-8
In [2]: a.encode('utf-8')
Out[2]: b'A'
# We get an array of bytes
In [3]: list(a.encode('utf-8'))
Out[3]: [65]
# So we transform the result and get the integer
In [4]: list(a.encode('utf-8'))[0]
Out[4]: 65
# Finally we show the binary represantion of this character
In [5]: bin(list(a.encode('utf-8'))[0])
Out[5]: '0b1000001'
Now, let’s try different UTF encodings,
In [1]: 'A'.encode('utf-8')
Out[1]: b'A'
In [2]: 'A'.encode('utf-16')
Out[2]: b'\xff\xfeA\x00'
In [3]: 'A'.encode('utf-32')
Out[3]: b'\xff\xfe\x00\x00A\x00\x00\x00'
We see that the same character has different byte representation. Let’s check the underlying byte arrays
In [4]: list('A'.encode('utf-8'))
Out[4]: [65]
In [5]: list('A'.encode('utf-16'))
Out[5]: [255, 254, 65, 0]
In [6]: list('A'.encode('utf-32'))
Out[6]: [255, 254, 0, 0, 65, 0, 0, 0]
We can go further and verify that each of those byte arrays translates to "A"
In [7]: bytearray([65]).decode('utf-8')
Out[7]: 'A'
In [8]: bytearray([255, 254, 65, 0]).decode('utf-16')
Out[8]: 'A'
In [9]: bytearray([255, 254, 0, 0, 65, 0, 0, 0]).decode('utf-32')
Out[9]: 'A'
What is the use of this?
When dealing with data between different operating systems – like reading and writting files –, or sending data through the internet, we need different encodings. For instance, to send binary data through http requests sometimes it is required to use base64 encoding instead of the binary buffer.
Python exposes a module for this, called base64, and we can get an uniform representation for the same data,
In [20]: import base64
In [21]: base64.b64encode(b"A")
Out[21]: b'QQ=='
In [22]: base64.b64encode(bytearray([65]))
Out[22]: b'QQ=='
In [23]: base64.b64encode(bytearray("A".encode('utf-8')))
Out[23]: b'QQ=='
# Another approach worth of noting
In [26]: import codecs
In [27]: base64.b64encode(codecs.encode("A", "utf-8"))
Out[27]: b'QQ=='
Though I know is not the most enlightening example, you won’t be as lost as I was the first time I’ve encountered this, if you are using python just check the docs on strings, bytesarray, base64, and codecs and be sure to read the links below